3-25、现代智能算法在材料腐蚀大数据中的应用研究
孟金桃1,支元杰1,李卓林1,付冬梅1,杨焘1,张达威2,李晓刚2
1.北京科技大学自动化学院, 2.北京科技大学新材料技术研究院
摘要:新材料的研发突破会带来高新技术的革命性进展,并奠定制造业革命的竞争优势,因此在新材料研发模式变革的需求下,国家推出一系列材料基因组工程专项。本课题关注材料基因组工程中的主要技术之一,即材料大数据技术,包含数据库建立,以及大数据处理与挖掘两大方面。
面对材料腐蚀大数据挖掘工程,通用传统的数据处理技术出现了不少问题,如数据如何科学化存储、大量未标号数据无法利用、腐蚀速率预测模型对变量因素敏感、噪声数据干扰等等。针对其中的腐蚀监测数据存在异常噪声、带标签样本数据量极少和标签数据与材料所在的环境因素的对应关系较为敏感的三类问题,课题组利用现代智能数据挖掘方法,给予解决。
1)在基于变分模式分解的方法中,考虑到腐蚀监测大数据的噪声具有明显的高频震荡和周期性两个特点,因此利用一种频率分解方法,称为变分模式分解,将高频数据从原数据中分离出来,分离结果称为本征模态。实验中,本方法取8个不同高频特性的本征模态,对其进行自相关性分析,依据噪声信号的自相关性低的固有特征,能够将噪声高频震荡现象很好地去除。此外,部分噪声尖峰值存在周期特性,为此利用其本身的特征,最优化构造出与其相似的信号,称为噪声模板,能够通过原信号与噪声模板相减,对其进行剔除。本方法效果如图1所示。
2)基于证据融合的方法能够判别材料处于不同腐蚀等级的概率值,且对于大量的未标号样本,可直接假定其初始概率值,因此能够处理带极少标号样本的腐蚀大数据。不同腐蚀等级的概率值是由多个证据给定的,所谓证据就是腐蚀数据相互之间的支持度,即如果要判断某条腐蚀数据所表征的腐蚀等级,其他数据信息就作为该判断过程的证据;此外还为每一个证据设定一个可靠度,以此作为对证据的一种可信程度;

图1. 左图:原始腐蚀电压比数据, 右图:噪声干扰剔除后的数据
表1 不同站点下碳钢腐蚀样本统计表
等级 | 润湿时间
| 温度
| 湿度
|
|
| 样本数量 | |
C2 | 240-1220 | -1.7-11 | 43-64 | 6-23 | 8-25 | 4 | |
C3 | 4283-5205 | 10.7-15 | 69-75 | 16.5-30.7 | 1.9-29.2 | 4 | |
C4 | 4000-4572 | 7.4-8.2 | 86-87 | 4.0-5.3 | 301.3-667 | 2 | |
C5 | 3521-5304 | 10.7-18.4 | 81-84 | 83-149.5 | 17.8-26 | 2 | |
表2 不同站点下碳钢处于不同腐蚀等级概率表(红色表示最大概率值)
站点/腐蚀等级 | C2 | C3 | C4 | C5 |
DunHuang | 1 | 0 | 0 | 0 |
MoHe | 0.997 | 0.001 | 0.001 | 0.001 |
KuErLe | 1 | 0 | 0 | 0 |
Bergisch | 0 | 1 | 0 | 0 |
Fleet Hall | 0 | 1 | 0 | 0 |
Baracaldo | 0 | 1 | 0 | 0 |
Kvarnik | 0.022 | 0.027 | 0.949 | 0.022 |
Auby | 0.062 | 0.201 | 0.062 | 0.735 |
将多个不同可信程度的证据进行融合,共同给出腐蚀数据所表征的腐蚀等级的概率值。取碳钢在12个不同站点的大气腐蚀数据为例,基于ISO9223-2012中碳钢腐蚀速率分级标准,其统计情况如表1所示。从不同腐蚀等级中随机选取1个样本作为标签样本,表2是本算法给出的碳钢在其余8个站点下处于不同腐蚀等级的概率值,结果与基于ISO9223-2012标准得到的分级一致。
3)腐蚀大数据的变量因素繁多,使得如腐蚀速率这类标签数据可能对某些因素敏感,准确地捕捉到敏感因素项和腐蚀速率的对应关系,是在大数据条件下,对腐蚀速率预测准确的关键。基于随机森林的腐蚀速率预测方法,能够更为准确地识别各变量因素对腐蚀速率的作用关系,是处理腐蚀数据中变量因素敏感问题的一种解决方法之一。该方法由多个树模型组成,如图2所示。

图2. 随机森林的模型结构图和其中一棵树模型的示例
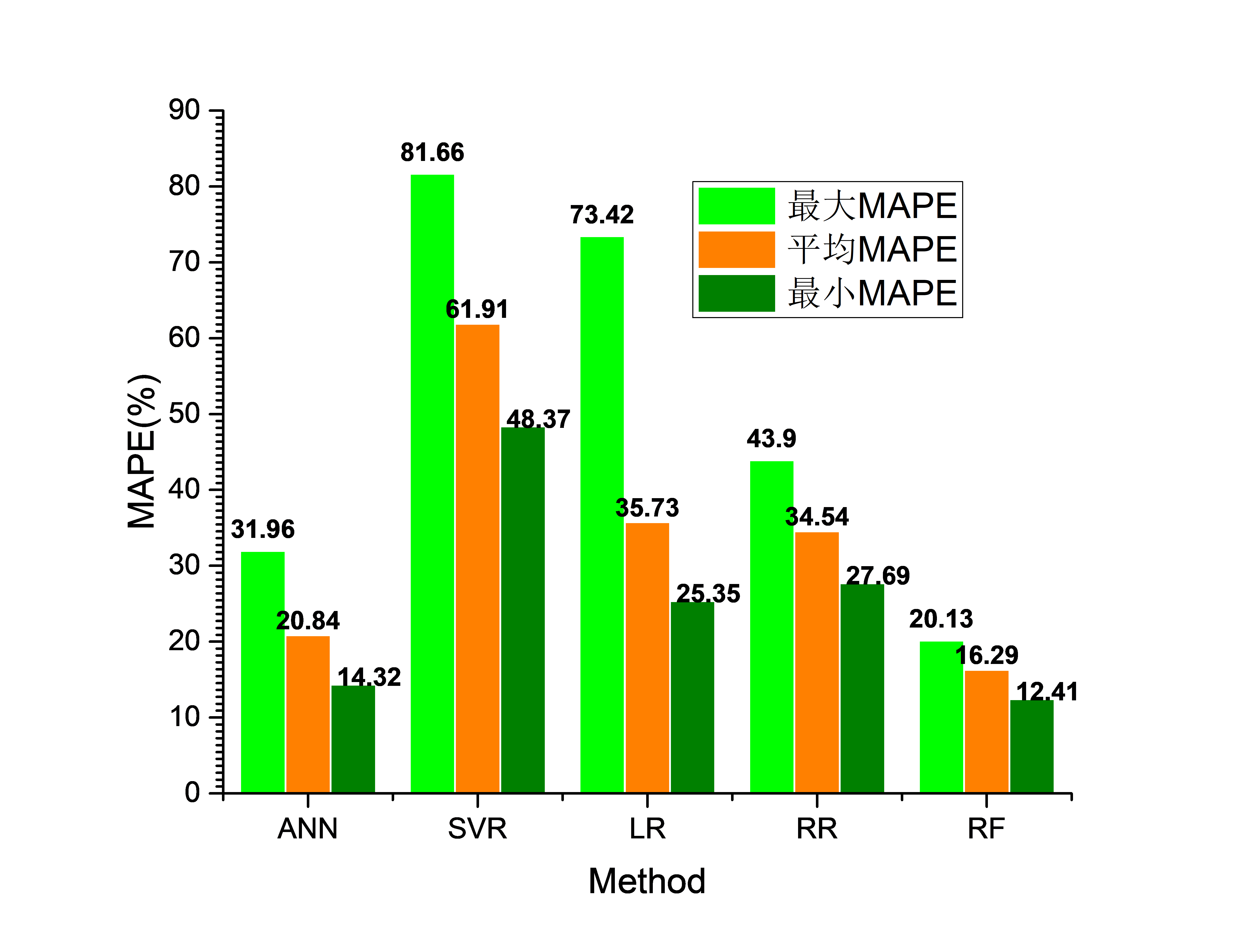
图3. 各腐蚀速率预测方法的对比结果(MAPE越小,预测越准确)
取来自于中国腐蚀与防护网的低合金钢大气腐蚀数据集进行预测仿真,并与多个数据挖掘方法对比。为体现本方法对腐蚀数据中的多变量因素敏感性的鲁棒程度,仿真过程进行了多次交叉验证,如图3给出平均、最大和最小的百分比误差值(MAPE),得出尤其是最大和最小MAPE间的差距明显小于其他算法,这表明了该方法在一定程度上克服了腐蚀速率与环境因素存在的敏感性。
本课题研究梯队将进一步深入人工智能、深度学习等策略,以腐蚀大数据为对象,针对数据建模、分析等过程中出现的特定特殊问题,在材料制备、研发和选材等各方面发挥一定作用。
致谢:国家重点研发计划“材料环境失效数据高效处理与利用技术”(2017YFB0702104)
DOI:10.12110/secondfmge.20181014.325

博士,北京科技大学自动化学院,控制科学与工程专业,数据挖掘与流形学习方向。2012年至2016年,在北京科技大学自动化学院攻读博士学位。2016年至2018年,在北京科技大学新材料技术研究院博士后流动站。2018年,丹麦技术大学数学与应用科学学院作访问学者半年。研究方向主要是流形理论在数据挖掘中的应用,腐蚀数据处理等。参与了科技部的国家材料环境腐蚀平台项目,和重点研发计划材料基因组工程专项子课题。